TinaCMS & Level.js
October 17, 2023
By Kelly Davis
TinaCMS is an open-source, Git-backed headless content management system (CMS) with a unique approach to content storage and retrieval. In this article, we are going to dive into its architecture and discover how Level.js strikes the perfect balance between simplicity and functionality needed by Tina.
The Challenge of Building a CMS on Git
One of the key features of TinaCMS is that instead of writing content to a database, it is stored in a Git repository. By using Git, Tina gets built-in version control and enables Git-based collaborative workflows. Similar to other headless CMS products, content is exposed for rendering using a queryable API that is generated using a developer-defined schema.
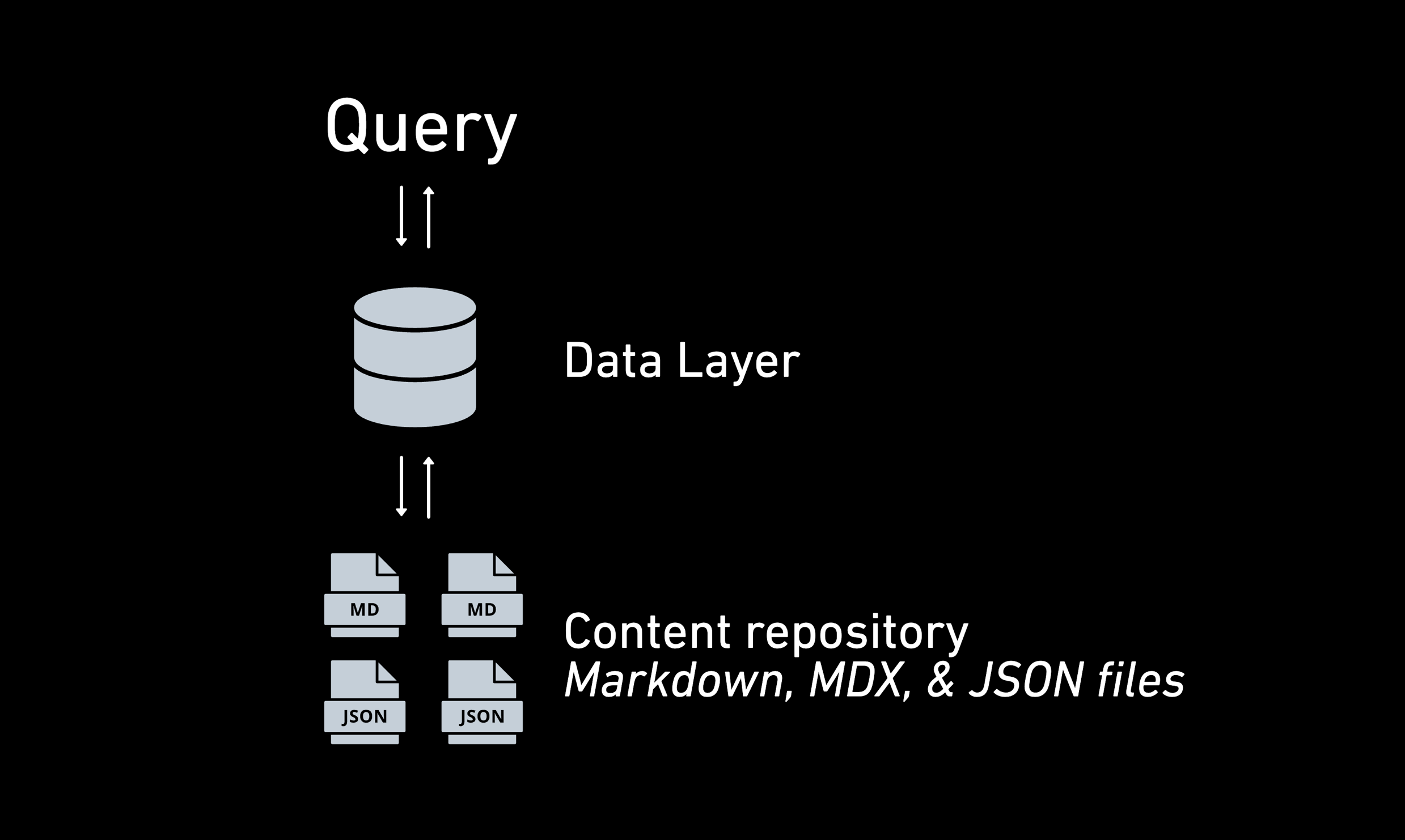
If Tina's API were to directly query the filesystem for content, it would be quite slow to access content, especially as the amount of content grows. Accessing individual documents and listing of files in a particular folder is straightforward. However, if we want to find all of the blog posts for a particular category, we have to load them all into memory, and then filter them before returning a result. Another common use case is ordering posts by the date they were authored. Unless we use a file naming scheme that incorporates a date field, sorting posts by date again would require loading all of the posts into memory and then sorting them before returning the sorted list. These solutions might be fine for a small site, but they are clearly not scalable.
For a typical headless CMS, the solution to this problem is to incorporate a database. A database provides both long term data storage and sophisticated scalable query capabilities. With a database, finding all the blog posts in a given category is as simple as adding a filter for the category field of a query to a posts table. Sorting is easily accomplished by identifying the field to sort by and specifying a sort direction. A typical database is also going to easily scale to the number of documents required by even the largest of web sites.
It’s self-evident, then, that Tina’s content API cannot rely solely on the Git file system. Some kind of hybrid solution incorporating both a database for scalable query capabilities and Git for storage and version control is needed. In our search for the right database solution for Tina, we had three constraints that guided us:
- When developing locally or self-hosting, developers should be able to use whichever database they prefer
- It should be easy to get up and running
- Behavior should be absolutely consistent between local development and production environments
Discovering Level.js
A Brief History
In 2010 Mozilla took a position against the Web SQL Database standard developed by Apple. As Arun Ranganathan argued:
We don’t think it is the right basis for an API exposed to general web content, not least of all because there isn’t a credible, widely accepted standard that subsets SQL in a useful way. Additionally, we don’t want changes to SQLite to affect the web later, and don’t think harnessing major browser releases (and a web standard) to SQLite is prudent.
Mozilla instead championed the simpler Indexed Database API standard (IndexedDB). This standard has a simpler and more stable API for developers to rely upon than Web SQL. It exposes a Javascript API over a NoSQL database. It also provides more storage over the existing Web storage standard.
Subsequently in 2011, to little fanfare, prolific Google engineers Jeffrey Dean and Sanjay Ghemawat released the LevelDB library. This open source project was a reimplementation of a subset of Google’s BigTable, in particular the Sorted String Table (SSTable) and log-structured merge-tree (LSM tree) concepts. Dean & Ghemawat contributed the newly released library to the Chromium project and since then it has been used for the Chrome web browser’s IndexedDB implementation [2][3].
What Makes LevelDB Stand Out?
LevelDB is a sorted key-value store. Keys are written in order on disk, allowing fast sequential reads, making range queries incredibly fast. It’s also possible to rapidly iterate over a range of keys starting and ending from anywhere in the database. Keys and values are both arbitrary byte arrays, so any data type can be used for either. The LSM tree architecture also allows both random and sequential writes that outperform other embedded databases as demonstrated in these benchmarks by Kevin Tseng.
While, any application that stores data locally can potentially benefit from using LevelDB, its unique characteristics make it well suited for applications that require fast and efficient data storage, retrieval, and management, particularly those with high read and write demands, the need for sorted data, or where low-latency access to key-value pairs is essential for optimal functionality. Both mobile and desktop applications that need efficient offline data capabilities are a good use case for LevelDB.
Arguably of greater significance than the performance of the LevelDB implementation, though, is the simple sorted key-value design shaped by the requirement to provide a standardized data API for the web. This simple and elegant API enables it to be more than just another embedded database library. On the one hand, the small set of API functions is deceptively versatile, enabling sophisticated database functionality using only a small set of primitives. On the other hand, the simplicity of the sorted key/value design means it can be implemented trivially by virtually any existing database. As an example, implementing it in a SQL database requires just a two column table with a primary key and a column for the value. As long as keys can be sorted and range queries can be executed, it is possible to support the LevelDB API. Because of the limited feature set, this design had the potential to be a powerful common database interface.
Level.js and Node.js: A Philosophical Harmony
In August 2012, Rodd Vagg released the first version of the LevelUP library, a Node.js LevelDB wrapper, which exposed LevelDB’s features in a Node.js-friendly way. Keys and values are treated as Buffer objects and reads and writes are done via streams. Early the following year, the LevelDB binding code was extracted into the LevelDOWN library as a standalone backend store and then support for other stores was enabled with the abstract-leveldown library. This soon led to a proliferation of other stores backed by well known database technologies such as Redis, MySQL, and DynamoDB. This community and ecosystem would eventually evolve into what is now referred to as Level.js.
In addition to the myriad stores available, there was an accompanying proliferation of modules extending the core of LevelDB to provide functionality common in more full featured databases. For example, since LevelDB is embedded, it does not provide any means of sharing access to its data across processes or over a network. Instead of adding that capability into the LevelDB core, developers wrote libraries which added that functionality such as Julian Gruber’s multilevel library.
This development approach is very much in harmony with the Node.js philosophy of having a small set of core functionality and leaving the remaining features as an ecosystem of modules outside of the core. Because of this philosophy, the Level.js ecosystem largely mirrored the larger Node.js community, with an explosion of small modules providing sophisticated functionality built around a stable core of limited functionality.
Why Level.js was the right choice for Tina
With Level.js, Tina gets the benefits of an embedded database in local development, making it very easy to get up and running without the effort of setting up a database. Because of the simple API design, Tina can also support virtually any hosted database that has a Level.js store implementation, while providing an absolutely consistent feature set. Level.js also provides a lot of flexibility to layer on additional functionality without impacting developer or end user experience. The reason for this goes back to its adherence to the Node.js philosophy of a compact stable core with additional functionality provided in userland.
As an example, in order to provide sorting beyond the default filename sorting, Tina implements database indexes derived from content metadata. These indexes are separated from the content data using a Level.js feature called sub-levels [4]. If we had been using a traditional database, adding a new index would have simply involved executing some DDL to identify the field being indexed and letting the database handle the rest. Because Level.js indexes are implemented in code, this feature in Tina required more initial development effort. Once this feature was added, though, it was then available to any Level.js store implementation that might be used in the future.
At this point, some readers might wonder how Tina handles schema migrations given this indexing functionality. What happens in the database, if a field that was being indexed is removed from the Tina schema? This is where the hybrid nature of Tina’s database really shines. Because Tina ultimately reads and writes content to the Git repository and doesn’t rely on the database for long term storage, the content and index data can be considered ephemeral. If the schema changes (or if the logic used to index the data changes), we can simply drop the existing data and rebuild it from the source of truth (Git). This provides a great deal of flexibility for us as we continue to iterate and improve the data layer and allows hassle-free schema updates for developers.
Beyond Databases: Search & Level.js in Tina
The benefits of using Level.js in Tina go beyond just powering the Tina API. We recently added a search feature that allows the editor to perform full text searches to locate content.
Originally, we planned on providing some integration with an existing solution like Algolia, but again we wanted to enable the simple local development experience while maintaining consistency between local development and hosted production sites. The solution presented itself in Fergus McDowall’s search-index library. This library provides an embeddable full-text search engine and is built on top of Level.js. Because it uses Level.js, it can be used with any database that has a Level.js store implementation. Using this library, Tina is able to provide full featured search both in local development and in the production hosted site with full feature parity.
Conclusion
LevelDB emerged from the necessity for an embedded database capable of supporting a standardized API for web data storage, coinciding with the rise of the burgeoning Node.js community. Remarkably, despite the absence of a robust marketing campaign, forward-thinking Node.js developers recognized its potential and nurtured it into the thriving Level.js ecosystem we witness today. With its compact yet robust core functionalities and the rich diversity of its ecosystem, Level.js has become the cornerstone of Tina's content API even a decade after its initial release. If you find yourself embarking on a new project without a definitive database solution, we wholeheartedly recommend exploring Level.js. Its elegant simplicity has endowed Tina with unparalleled flexibility and a solid foundation for future innovations. Dive deeper into Level.js's capabilities at leveljs.org and unlock a world of possibilities.
Footnotes
- [1] Web SQL is currently scheduled for removal from Chrome in November 2023: https://developer.chrome.com/blog/deprecating-web-sql/
- [2] See chrome://credits/
- [3] Somewhat ironically, Mozilla Firefox is still using SQLite for its implementation of IndexedDB.
- [4] In older versions of Level.js, this feature was provided by a module, but has since been incorporated into the core library.
Last Edited: October 17, 2023